|
News
02.2026 One paper accepted by CVPR '26 Finding track! Check out the VCR!!🎉
02.2025 One paper accepted by CVPR '25! Check out the SocialGesture!!🎉
10.2024 One paper accepted by ECCV '24! Check out the EgoGaze!!🎉
04.2024 Passed my Qualifier! I will transfer to UIUC in Fall 24. 🌽🌽🌽🧐🌽🌽🌽
02.2024 One paper accepted by CVPR '24! Check out the AV-CONV!!🎉🤹♀️
08.2022 One journal paper accepted by TNNLS! 🎉
07.2022 One paper accepted by ECCV '22!! 🎉✡️
03.2022 Our Ego4D paper has been accepted by CVPR '22 as an oral paper! 🥂
|
|
|
|
|
IAM: Identity-Aware Human Motion and Shape Joint Generation
Wenqi Jia,
Zekun Li,
Abhay Mittal,
Chengcheng Tang,
Chuan Guo,
Lezi Wang,
James Matthew Rehg,
Lingling Tao,
Sizhe An
(Under Review)
project /
paper /
code
|
|
|
Learning Predictive Visuomotor Coordination
Wenqi Jia,
Bolin Lai,
Miao Liu,
Danfei Xu†,
James M. Rehg†
CVPR, 2026, Findings
project /
arxiv /
code
|
|
|
Toward Human Deictic Gesture Target Estimation
Xu Cao,
Pranav Virupaksha,
Sangmin Lee,
Bolin Lai,
Wenqi Jia,
Jintai Chen,
James M. Rehg†
NeurIPS, 2025
project /
paper /
code
|
|
|
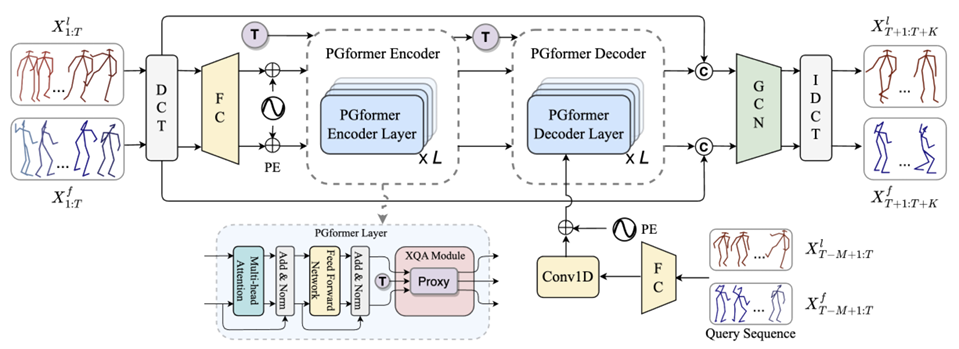
PGFormer: Proxy-Bridged Game Transformer for Interactive Extreme Motion Prediction
Yanwen Fang,
Wenqi Jia,
Xu Cao,
Peng-Tao Jiang,
Guodong Li,
Jintai Chen
ICCV, 2025
paper
/
code
|
|
|
SocialGesture: Delving into Multi-person Gesture Understanding
Xu Cao,
Pranav Virupaksha,
Wenqi Jia,
Bolin Lai,
Fiona Ryan,
Sangmin Lee,
James M. Rehg†
CVPR, 2025
project /
arXiv /
code /
dataset
|
|
|
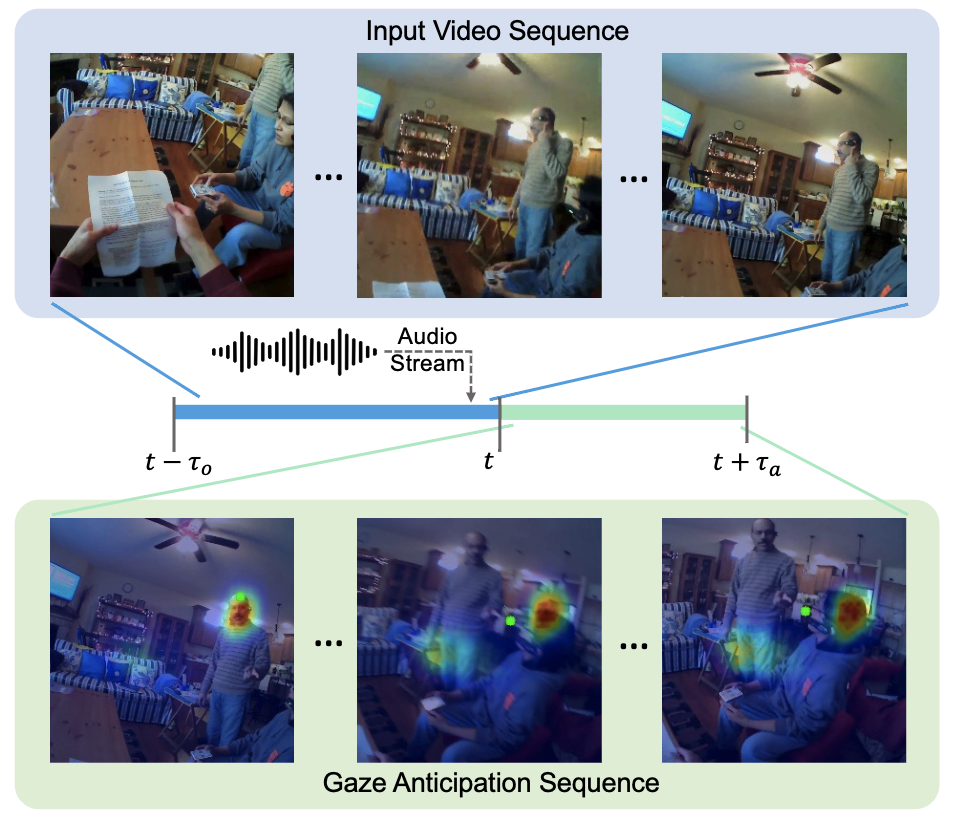
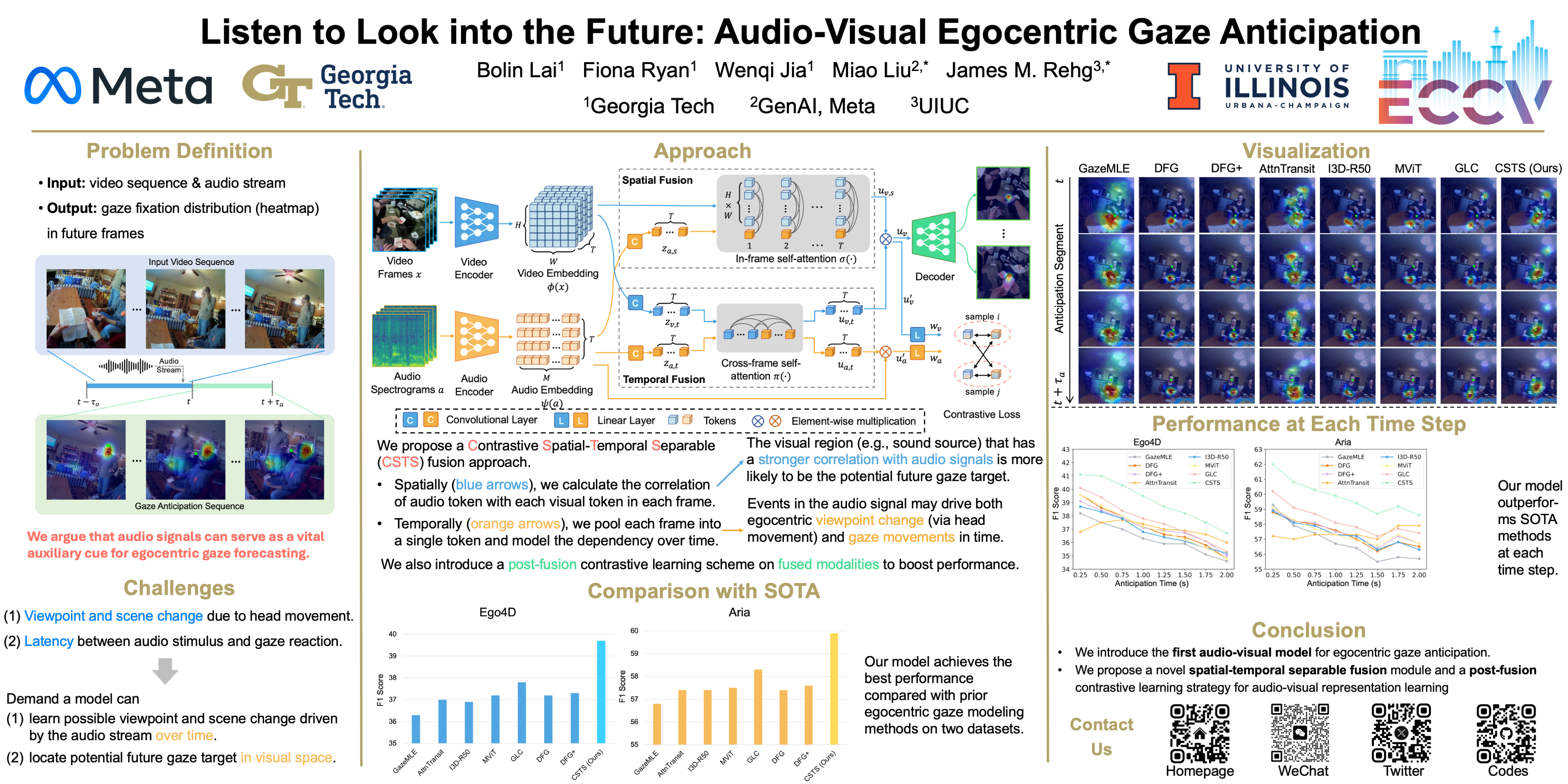
Listen to Look into the Future: Audio-Visual Egocentric Gaze Anticipation
Bolin Lai,
Fiona Ryan,
Wenqi Jia,
Miao Liu†,
James M. Rehg†
ECCV, 2024
project /
paper /
code /
data Split /
supplementary /
video /
poster
|
|
|
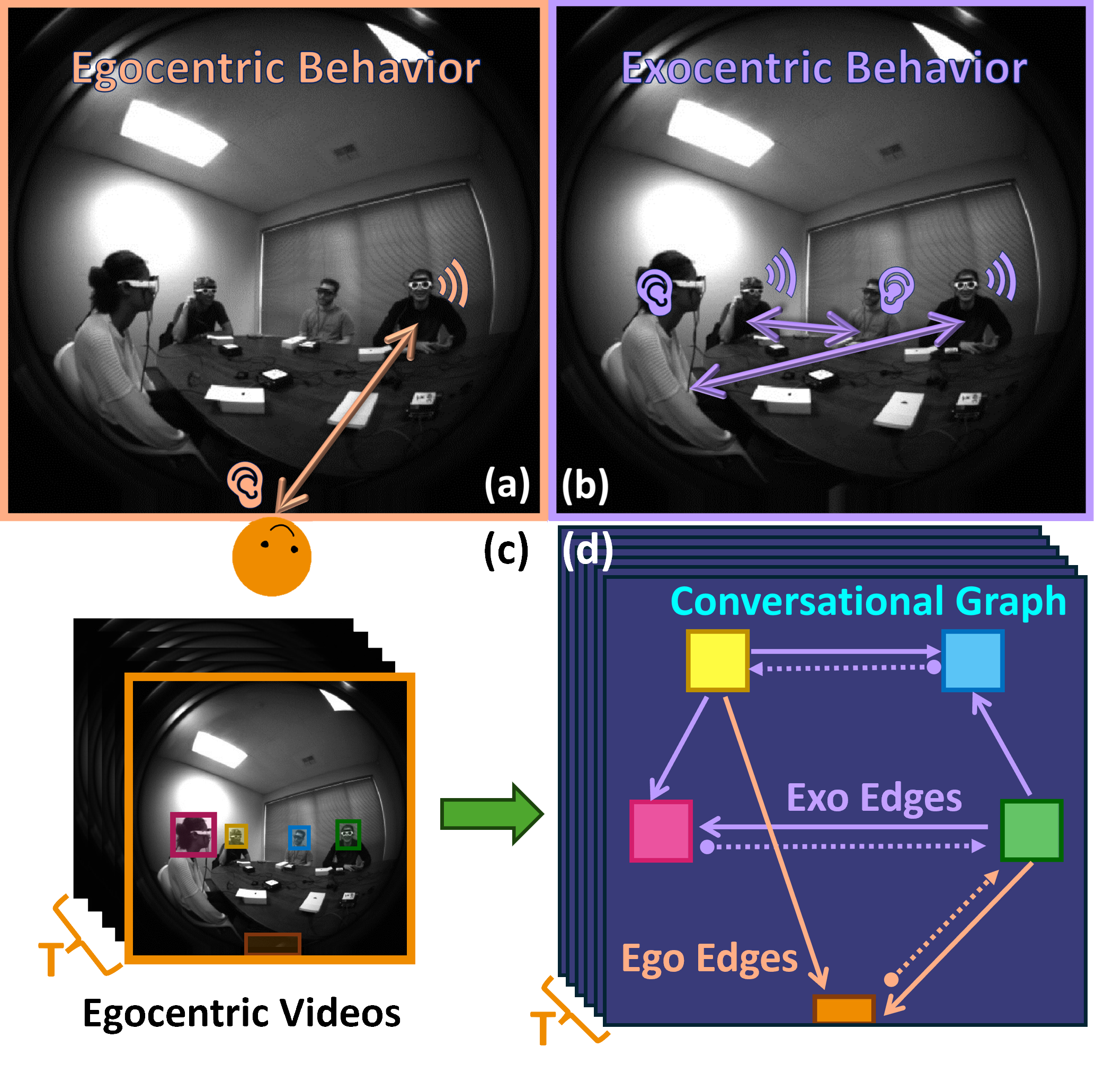
The Audio-Visual Conversational Graph: From an Egocentric-Exocentric Perspective
Wenqi Jia,
Miao Liu,
Hao Jiang,
Ishwarya Ananthabhotla,
James Rehg†,
Vamsi Krishna Ithapu†,
Ruohan Gao†
CVPR, 2024
project /
paper /
code /
bibtex
(⇐ Move your cursor on the image for a short demo video!)
|
|
|
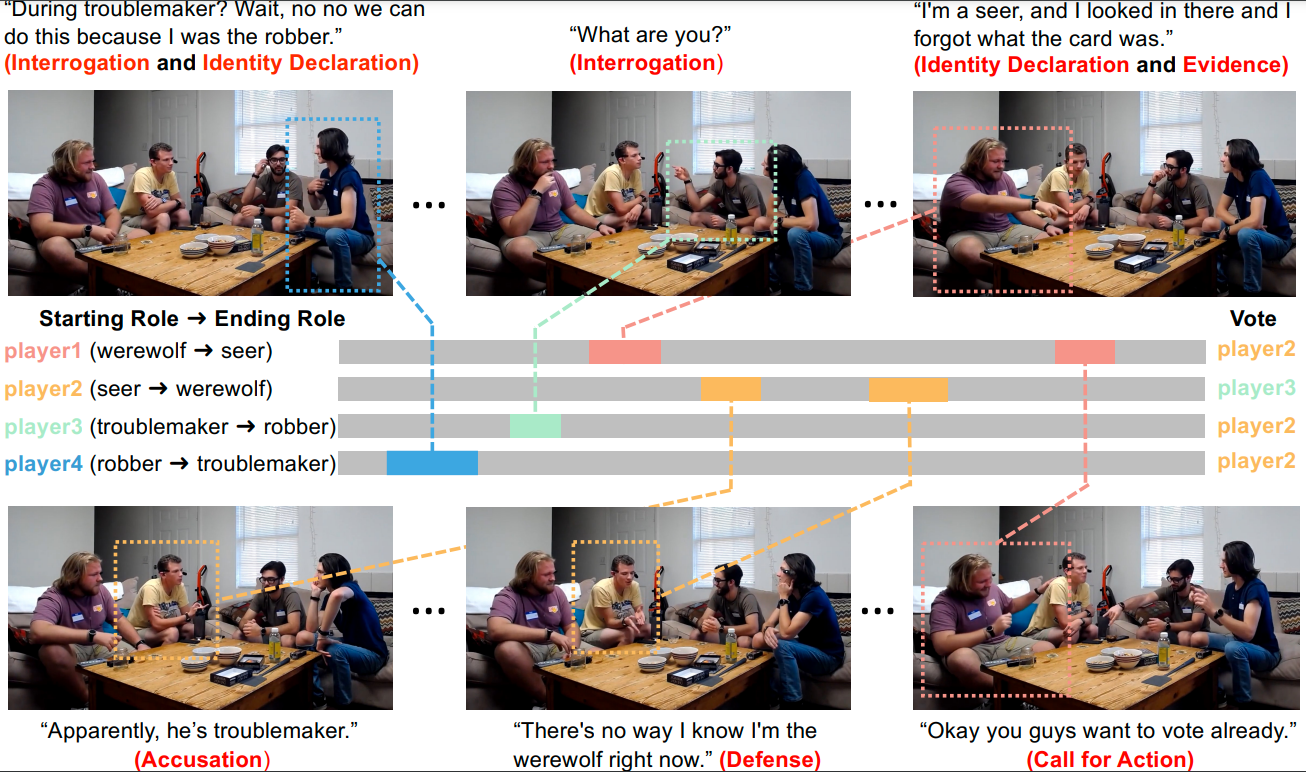
Werewolf Among Us: A Multimodal Dataset for Modeling Persuasion Behaviors in Social Deduction Games
Bolin Lai,
Hongxin Zhang,
Miao Liu,
Aryan Pariani,
Fiona Ryan,
Wenqi Jia,
James Rehg†,
Diyi Yang†
ACL Findings, 2023
project /
paper /
bibtex
|
|
|
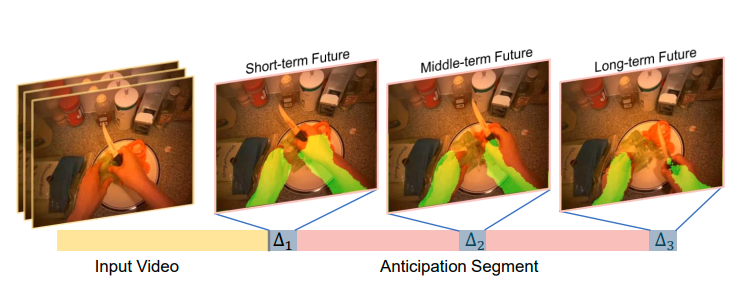
Generative Adversarial Network for Future Hand Segmentation from Egocentric Video
Wenqi Jia,
Miao Liu,
James Rehg†
ECCV, 2022
project /
paper /
code /
supplement /
poster /
video /
bibtex
(⇐ Move your cursor on the image for a short demo video!)
|
|
|
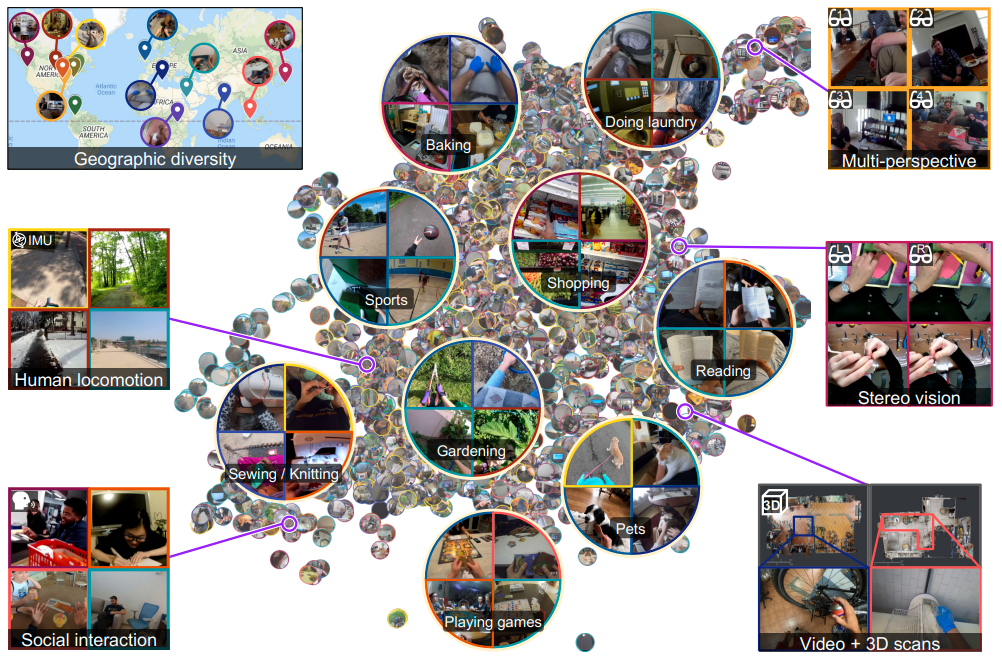
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Kristen Grauman, et al.
CVPR, 2022 (Oral)
project /
paper /
code /
dataset /
video /
bibtex
|
|
|
Paying More Attention to Motion:
Attention Distillation for Learning Video Representations
Miao Liu,
Wenqi Jia,
Xin Chen,
Yun Zhang,
Yin Li,
James Rehg†
IJCV, 2021 (Special Issue) (under review)
arXiv /
code /
bibtex
|
|
|
Holistic-Guided Disentangled Learning With Cross-Video Semantics Mining for Concurrent
First-Person and Third-Person Activity Recognition
Tianshan Liu,
Wenqi Jia,
Rui Zhao,
Kin-Man Lam†,
Jun Kong
TNNLS, 2022
paper /
bibtex
|
Academic Service and Volunteer Work
- Reviewer 🔎, CVPR, ECCV, BMVC, ICCV
- Certified First Responder 🚑, Hong Kong Red Cross, Jun 2015 - Jun 2019
|
|





{kind=link}